Deep Declarative Networks
CVPR 2020 Workshop, 14 June, Seattle, Washington, USA
(15 June 2020): All recorded talks are available here.
Program | Speakers | Papers | Submission | Dates | Organizers
Conventional deep learning architectures involve composition of simple feedforward processing functions that are explicitly defined. Recently, researchers have been exploring deep learning models with implicitly defined components. To distinguish these from conventional deep learning models we call them deep declarative networks, borrowing nomenclature from the programming languages community (Gould et al., 2019).
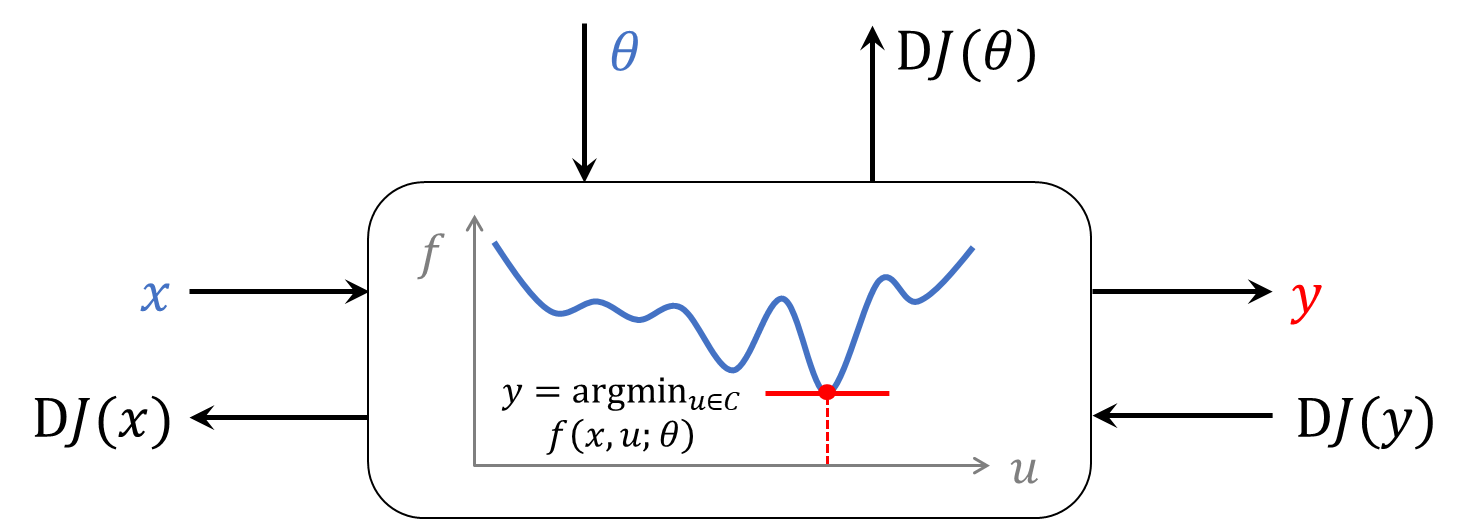
Processing nodes in deep declarative networks involve solving an optimization problem in the forward pass. End-to-end learning back-propagates gradients through the node, which requires the optimization problem to be differentiable. A few recent works have studied various optimization problem classes and shown how backpropagation is possible even without the knowledge of the algorithm used for solving the problem in the first place (Agrawal et al., 2019b; Agrawal et al., 2019a; Amos, 2019; Pfau et al. 2019; Amos and Kotler, 2017; Gould et al., 2016). The ideas have been applied to various problems including video classification (Fernando and Gould, 2016; Cherian et al., 2017, Wang and Cherian, 2019), attribute ranking (Santa Cruz et al., 2018), meta-learning (Lee et al., 2019), and model predictive control (Amos et al., 2018).
Variants of deep declarative networks have also been studied recently such as methods for imposing hard constraints on the output of neural network models (Neila et al., 2017), novel models based on back-propagating through ordinary differential equations (Chen et al., 2018), approximating maximum satisfiability (MAXSAT) problems (Wang et al., 2019), and combinatorial submodular functions (Tschiatschek et al., 2018).
Topics
This workshop explores the advantages (and potential shortcomings) of declarative networks and their variants, bringing ideas developed in different contexts under a common umbrella. We will discuss technical issues that need to be overcome in developing such models and applications of these models to computer vision problems that show benefit over conventional approaches. Topics include:
- Declarative end-to-end learnable processing nodes
- Differentiable constrained and unconstrained (non-convex) optimization problems
- Differentiable convex optimization problems
- Imposing hard constraints in deep learning models
- Back-propagation through physical models
- Applications of the above to problems in computer vision such as differentiable rendering, differentiable 3d models, reinforcement learning, action recognition, meta-learning, etc.
Program
The workshop is 100% virtual and will run as a 12+12 format, 9:15am (14 June) to 4:00pm (14 June) PDT and repeating 9:15pm (14 June) to 4:00am (15 June) PDT. The program includes a mix of live and pre-recorded talks, Q&A and poster sessions, and asynchronous discussion forums. Times below are given for the first instance; add 12 hours for the repeated sessions.
| Time (PDT) | Time (EDT) | Time (CEST) | Time (AEST) | Session |
|---|---|---|---|---|
| 9:15am | 12:15pm | 6:15pm | 2:15am | Welcome |
| 9:30am | 12:30pm | 6:30pm | 2:30am | Invited talk #1 (Amos) |
| 10:00am | 1:00pm | 7:00pm | 3:00am | Invited talk #2 (Chen) |
| 10:30am | 1:30pm | 7:30pm | 3:30am | Invited talk #3 (Finn) |
| 11:00am | 2:00pm | 8:00pm | 4:00am | Break |
| 11:15am | 2:15pm | 8:15pm | 4:15am | Paper orals |
| 12:30pm | 3:30pm | 9:30pm | 5:30am | Poster session |
| 2:00pm | 5:00pm | 11:00pm | 7:00am | Invited talk #4 (Fua) |
| 2:30pm | 5:30pm | 11:30pm | 7:30am | Invited talk #5 (Maji) |
| 3:00pm | 6:00pm | 12:00am | 8:00am | Invited talk #6 (Kolter) |
| 3:30pm | 6:30pm | 12:30am | 8:30am | Closing remarks |
- AEST is +1 day.
Invited Speakers






Accepted Papers
- Zan Gojcic, Caifa Zhou, Jan D. Wegner, Leonidas J. Guibas and Tolga Birdal, “End-to-end globally consistent registration of multiple point clouds”. [pdf | oral | live Q&A]
- Edward Grefenstette, Brandon Amos, Denis Yarats, Phu Mon Htut, Artem Molchanov, Franziska Meier, Douwe Kiela, Kyunghyun Cho and Soumith Chintala, “
higher: A Pytorch Meta-Learning Library”. [pdf | oral | live Q&A] - Krishna Murthy Jatavallabhula, Ganesh Iyer, Soroush Saryazdi and Liam Paull, “∇SLAM: Automagically differentiable SLAM”. [pdf | oral | live Q&A]
- Bashir Sadeghi, Lan Wang and Vishnu Boddeti, “Adversarial Representation Learning With Closed-Form Solvers”. [pdf | oral | live Q&A]
- Matteo Toso, Neill D. F. Campbell and Chris Russell, “Fixing Implicit Derivatives: Trust-Region Based Learning of Continuous Energy Functions (Abridged)”. [pdf | oral | live Q&A]
Submission
We invite paper submissions of up to four (4) pages describing work in areas related to the workshop topics.
Accepted submissions will be presented as short orals or posters at the workshop and will appear on the workshop website. Authors will be given an opportunity to revise the submission before posting on the website. Papers should follow the CVPR formatting guidelines and emailed as a single PDF to cvpr2020@deepdeclarativenetworks.com, with subject line Paper: <title>. Submissions are not anonymous (and should include all authors’ names and affiliations). References are to be included in the 4-page limit.
Dual Submissions
We encourage submissions of preliminary or ongoing work. Accepted papers will not appear in the official IEEE proceedings but will be made public on this website. Relevant work that has previously been published or is to be presented at the main conference is also welcome.
Important Dates
- Submission deadline:
1 March 202020 March 2020 (extended) - Author notification: 13 April 2020
- Workshop camera-ready deadline: 8 May 2020
- Workshop date: 14 June 2020
Organizers




Contact: cvpr2020@deepdeclarativenetworks.com